The Security
Hyperautomation Pioneer
The enterprise-grade, AI-driven hyperautomation platform that makes autonomous security operations a reality
Your Security Product’s Favorite Security Product
80%
of orgs agree SOAR is too complex,
costly, and time-consuming
![]() 2022 ESG Report
2022 ESG Report
10X Faster ROI
Than Legacy SOAR
Create and deploy complex, sophisticated workflows in minutes
Enterprise Architecture
Cloud-native, multi-tenant, zero-trust architecture that scales with your needs
Connect to Everything
Hyperautomate every app, every stack, across cloud, on-premise, and hybrid environments
No-Code or Your Code
Go beyond APIs, with support for any CLI, platform, and programming or scripting language
Industry Analysts, Agree…
Hyperautomation Signals End of SOAR Era
![]()
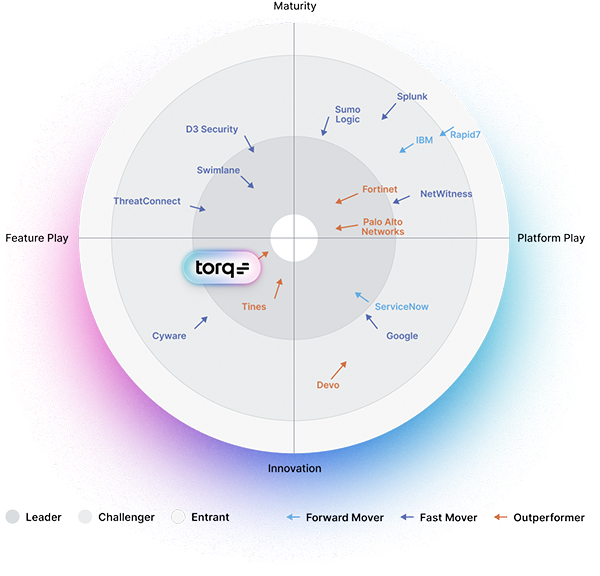
“Torq offers an extensive feature set, as reflected in its high scores across most of the key criteria, including case management, and collaboration, automated alert prioritization, triage and curation, autonomous operations, and validation and red teaming, and has acquired an impressive portfolio of customers.”
GigaOm Radar 2023

![]()
In the most detailed security hyperautomation study to date, leading analyst firm IDC looks at how hyperautomation precisely “predicts security gaps, proactively assesses the network, and ultimately secures it” by delivering “visibility and control of all environments for all processes and role players.”
IDC Report
"We now query 2,000+ assets in under 7 minutes with Torq, which previously took over an hour to run, one at a time. This reflects an 800% improvement in execution time."

“Torq is a great automation tool that makes security processes and workflows easy to implement in a very secure way.”
"After researching and testing several different SOAR platforms, Torq quickly became the obvious answer for our organization. We have already saved thousands of man hours on repeatable tasks, and I've barely scratched the surface."
“Single solution for all security automation and tools that the security team needs…The best support I ever received from any vendor.”
“Torq's hyperautomation platform is a game-changer in the cybersecurity landscape. Its ability to rapidly identify, integrate, and automate a wide range of business and IT processes is truly impressive.”
Protecting World-Class Enterprises
Fortune 500 enterprises, including the world’s biggest financial, technology, consumer packaged goods, fashion, hospitality, and sports apparel companies are experiencing extraordinary outcomes with Torq.

San Francisco | May 6-9, 2024 | Booth #4415


